
Зачем вообще нужна гибкая система обновлений статистики матчей
Если вы хоть раз ловили лаги на трансляции и видели, как счёт на экране не совпадает с реальным, вы уже понимаете, зачем это всё нужно. Гибкая система обновлений статистики матчей — это не «ещё один модуль», а связующее звено между полем, судьями, операторами данных, букмекерами, медиа и конечными зрителями.
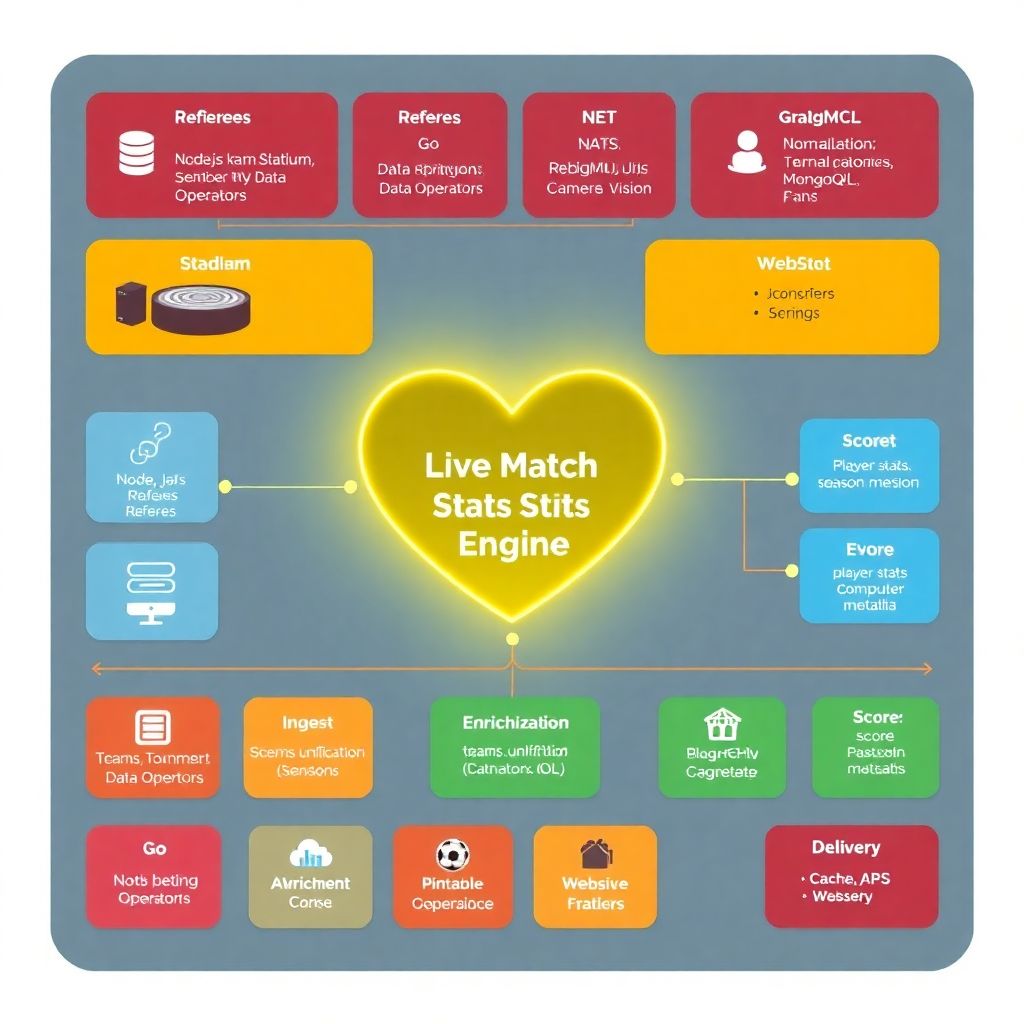
По сути, это сердце любой современной системы онлайн статистики спортивных матчей: она собирает события (голы, фолы, владение, броски, замены), нормализует их, валидирует, отдаёт наружу через API и при этом не ложится при пиковых нагрузках.
Необходимые инструменты и архитектурный фундамент
Технологический стек: от сбора до выдачи
Для гибкости важна не конкретная технология, а модульность. Но без базового набора инструментов далеко не уедешь. Типичная платформа live-статистики для спортивных соревнований опирается на такие компоненты:
— Бэкенд-фреймворк: Node.js, Java (Spring), .NET, Go — любая производительная серверная платформа.
— Брокер сообщений: Kafka, RabbitMQ, NATS — для событийной обработки.
— Хранилища:
— оперативное (Redis, Memcached) для live-данных;
— долгосрочное (PostgreSQL, ClickHouse, MongoDB) для истории.
— API-шлюзы: REST и/или GraphQL, иногда WebSocket-шлюз для пуш-обновлений.
Верхним уровнем крутится программное обеспечение для обновления статистики матчей: админ-панели для операторов, интерфейсы для приёма данных от провайдеров, модули интеграции с внешними сервисами.
Где брать и как фильтровать спортивные данные
Источники данных сильно влияют на архитектуру. Обычно это смесь трёх каналов:
— Официальные фиды лиг и федераций (XML/JSON каналы событий).
— Операторы, работающие «с поля», через специализированные UI.
— Автоматические трекеры: сенсоры на форме, камеры и компьютерное зрение.
Разработка системы трекинга статистики спортивных игр в 2025 году всё чаще включает компьютерное зрение и машинное обучение. Сырая телеметрия переводится в «человеческие» события (пас, удар, подбор), а дальше обрабатывается уже как единый поток.
Поэтапный процесс построения гибкой системы
Шаг 1. Формализация требований и SLA
Сначала нужно честно ответить на пару неудобных вопросов: кто конечный потребитель, какие задержки допустимы, насколько критична точность, сколько матчей нужно тянуть одновременно.
На этом этапе формируются SLA:
— максимальная задержка обновления (например, не более 1–2 секунд);
— допустимая деградация (какие метрики можно временно урезать при перегрузке);
— RPO/RTO для отказоустойчивости (через сколько всё должно подняться после сбоя).
Шаг 2. Проектирование событийной модели
Гибкость начинается с правильной модели событий. Вместо того чтобы жёстко прошивать «удар», «гол», «угловой» в код, удобнее описать их как типы событий с набором атрибутов.
Ключевые моменты:
— каждое событие — неизменяемое (event sourcing-подход);
— версия схемы событий позволяет эволюционировать модель без остановки системы;
— все события имеют глобальный уникальный идентификатор и временную метку с источником.
Такое проектирование упрощает добавление новых видов спорта или метрик без полного рефакторинга.
Шаг 3. Построение конвейера обработки
Дальше организуем «конвейер»:
— Ингест-слой — приём данных из внешних фидов, UI операторов, сенсоров.
— Нормализация — приведение к единому формату, валидация, дедупликация.
— Обогащение — добавление контекста (команды, турниры, метаданные о сезонe).
— Агрегация — расчёт счёта, статистики игрока, командных показателей.
— Доставка — пуш в кэш, API, WebSocket-подписки, внешние интеграции.
Важно, чтобы каждый этап был отдельным сервисом или модулем, а не одним монолитом «на всё». Именно это даёт гибкость при изменениях.
Шаг 4. Реализация API и режимов доступа
В 2025 году потребители статистики становятся всё разнообразнее: от мобильных приложений болельщиков до аналитических систем клубов.
Обычно нужны сразу несколько интерфейсов:
— REST API для запросов к историческим и текущим данным;
— WebSocket или SSE для live-подписок;
— внутренние сервисные API для интеграции с биллингом, CRM, антифродом.
Хорошая практика — версионировать API и заранее закладывать backward compatibility, чтобы обновление логики не ломало клиентов.
Шаг 5. Настройка масштабирования и отказоустойчивости
На этапе внедрения тестируется поведение системы под нагрузкой: тысячи параллельных матчей, всплеск подключений во время решающих минут, массовые запросы к live-ленте.
Используются:
— горизонтальное масштабирование микросервисов;
— отдельные кластеры кэша под горячие данные;
— репликация и шардинг БД;
— автоматическое переключение на резервные фиды статистики при сбоях основного источника.
Устранение неполадок и типовые сбои
Классические симптомы: лаги, расхождения, дубли
Проблемы обычно проявляются в трёх формах: задержка обновлений, некорректные значения и дублирующиеся события.
Частые причины:
— потеря сообщений в брокере при неверной конфигурации очередей;
— десинхронизация времени между источниками данных;
— некорректная обработка повторных поставок (re-delivery) от провайдеров.
Для диагностики помогают:
— трассировка событий end-to-end с корреляционными ID;
— дашборды задержек по каждому этапу конвейера;
— отдельный лог «непонятных» событий, требующих ручной проверки.
Экстренные сценарии: как не подвести во время топ-матча

Самые критичные инциденты случаются как раз на финалах и дерби. Поэтому у гибкой системы должен быть режим «деградировать, не падать».
Типичные меры:
— временно отключать второстепенные метрики (xG, продвинутые трекеры) в пользу базовых — счёт, фолы, замены;
— переводить часть потребителей на кешированные данные с небольшой задержкой;
— включать резервных операторов для ручной корректировки ключевых событий.
Хорошее программное обеспечение для обновления статистики матчей всегда имеет понятные инструкции для операторов: как отредактировать счёт, отменить событие, пометить матч как подозрительный, не влезая в код.
Как отличить баг от проблем данных
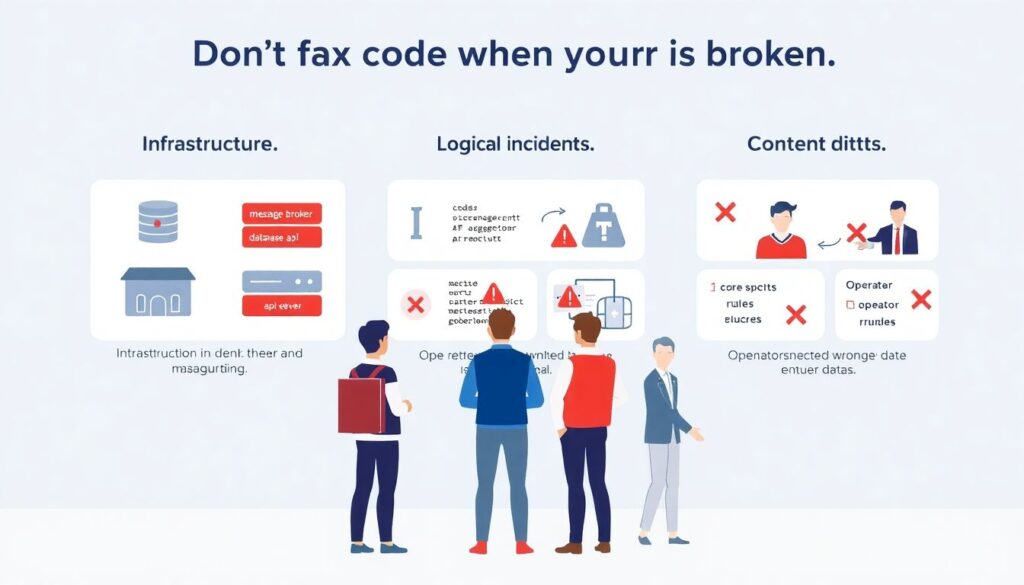
Частая ошибка команд — пытаться чинить код, когда сломан источник. Чтобы не тратить часы впустую, вводится разделение инцидентов:
— инфраструктурные (не отвечает брокер, база, API);
— логические (ошибки в коде агрегации и бизнес-правилах);
— контентные (неправильные данные от лиги, судьи, оператора).
Для контентных проблем обычно готовятся пара сценариев: ручное исправление, пометка матча как спорного, уведомление партнёров об обновлении статистики.
Гибкость как продукт: готовые решения и кастомная разработка
Когда есть смысл брать готовую платформу
Если речь идёт о типовой задаче — показывать счёт, базовую статистику и немного продвинутых метрик — часто выгоднее купить готовое решение для статистики спортивных матчей, чем строить всё с нуля. Особенно это актуально для медиа, небольших букмекеров и региональных лиг.
Готовые решения дают:
— заранее протестированный конвейер обработки;
— интеграции с популярными поставщиками данных;
— панели для операторов и аналитиков без доп. разработки.
Главный минус — меньшая гибкость под экзотические метрики и собственные алгоритмы анализа.
Когда оправдана собственная система
Кастомная разработка имеет смысл, если:
— вы хотите уникальные метрики, аналитические модели или свои алгоритмы оценки игроков;
— планируете глубокую интеграцию с внутренними системами клуба или лиги;
— работаете с редкими видами спорта или нестандартными форматами соревнований.
В этом случае разработка системы трекинга статистики спортивных игр превращается в стратегический проект: от выбора сенсоров и камер до построения аналитических витрин для тренерского штаба.
Прогноз развития: что будет с live-статистикой к 2030 году
Текущий рубеж: 2025 год
Сейчас, в 2025 году, рынок уже перешёл от простого сбора событий к их интерпретации. Профессиональные клубы ждут не просто цифры, а готовые инсайты: риск травмы, утомлённость игрока, оптимальные связки на поле.
Пара трендов уже закрепилась:
— массовое внедрение компьютерного зрения;
— переход к event-driven архитектурам;
— унификация протоколов передачи спортивных данных между лигами и провайдерами.
Ближайшие 3–5 лет: персонализация и предиктивность
Гибкая система обновлений статистики матчей будет всё больше напоминать «платформу принятия решений».
Ожидаются такие изменения:
— персонализированные фиды: разным пользователям — разные наборы метрик и уровни детализации;
— глубжеe использование ML для автообнаружения аномалий — подозрительных матчей, ошибок в судействе, нетипичных действий игроков;
— tight-интеграция с медиа: автоматическая генерация клипов по триггерам (xG-моменты, серии потерь и т.д.).
Платформа live-статистики для спортивных соревнований станет неотделимой частью всей медиа-экосистемы вокруг матчей, а не отдельным сервисом.
Долгосрочно: «невидимая» статистика в реальном времени
К 2030 году границы между трансляцией и аналитикой практически сотрутся. Для пользователя статистика станет «невидимой», но вшитой во всё:
— умные устройства будут показывать только релевантные метрики (например, на умных очках болельщика — индивидуальные показатели любимого игрока в реальном времени);
— тренерские штабы получат системы, где одни и те же события используются и для тактики, и для медицинского мониторинга, и для скаутинга;
— сам формат хранения данных сместится от «логов матчей» к «графам взаимодействий» между игроками, зонами и событиями.
На стороне инфраструктуры это означает ещё более жёсткие требования к гибкости: обновления моделей, пересборка метрик и изменения бизнес-логики должны происходить без остановки даже на миллионах одновременных зрителей.
Итог: на что делать ставку уже сейчас

Чтобы система онлайн статистики спортивных матчей оставалась актуальной в ближайшие годы, при проектировании стоит зафиксировать несколько принципов:
— событийная архитектура и чёткая модель домена;
— модульность конвейера обработки и возможность независимо обновлять отдельные этапы;
— сильное логирование, трассировка и инструменты диагностики, чтобы упрощать устранение неполадок;
— подготовка к интеграции с ML-модулями для предиктивной аналитики.
Тогда независимо от того, строите вы свой продукт или интегрируете готовую платформу, гибкая система обновлений статистики матчей сможет эволюционировать вместе с требованиями рынка, а не тормозить их.